 2021-07-07 09:39:27
2021-07-07 09:39:27
对于百度搜索引擎工作原理知识,很多站长SEO还没有认真阅读和理解,本文可以让SEOer对3358www.sina.com/捕获系统原理和索引数据库、SEOer对百度蜘蛛收录的索引库有更多的了解。(威廉莎士比亚,Northern Exposure(美国电视剧),搜索)。
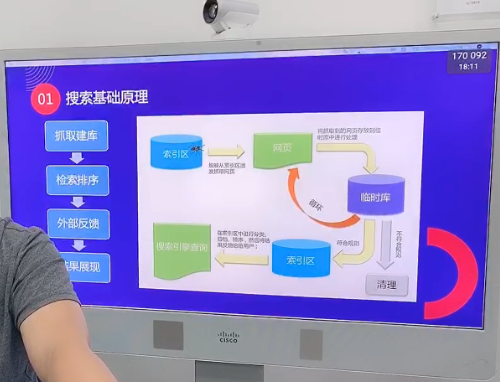
一,Spider 抓取系统的基本框架
网络信息呈爆炸式增长,如何有效地收集和利用信息是搜索引擎工作的最重要部分。数据收集系统是整个搜索系统的上游,主要负责网络信息的收集、保存和更新过程,像蜘蛛一样在网络之间爬行,因此通常被称为“spider”。例如,我们常用的几种通用搜索引擎蜘蛛被称为Baiduspdier、Googlebot、Sogou Web Spider等。
Spider捕获系统是搜索引擎数据源的重要保证。如果将web直接解释为图形,则Spider的工作流程可以认为是在这个直接图形中巡回。从一些重要的种子URL开始,通过页面的超链接关系不断发现和捕获新的URL,捕捉尽可能多的有价值的网页。对于Baidu等大型spider系统,网页总是有可能被修改、删除或出现新的超链接,因此spider需要保持以前捕获的页面的更新状态,以维护URL库和页面库。
下图是spider捕获系统的基本框架图,包括存储系统连接、链接选择系统、DNS分析服务系统、捕获调度系统、Web分析系统、链接提取系统、链接分析系统、Web存储系统。Baiduspider是通过该系统的合作完成对互联网页面的捕捉工作。
二,Baiduspider主要抓取策略类型
上图看起来很简单,但实际上Baiduspider在捕获过程中涉及到了非常复杂的网络环境。这使系统能够捕获尽可能多的有价值的资源,在系统和实际环境中保持页面一致性的同时,设计各种复杂的捕获战略,而不会给网站体验带来负担。以下是简单的介绍。
1. 抓取友好性
网络资源的庞大规模,为此,捕捉系统需要尽可能有效地利用带宽,在有限的硬件和带宽资源下捕捉尽可能多的有价值的资源。这引发了另一个问题,它会消耗被抓住站点的带宽,造成访问压力,如果程度太大,会直接影响被抓住站点的正常用户访问行为。因此,在捕获过程中必须进行一定的捕获压力控制,以便尽可能多地捕获不影响网站的最终用户访问和有价值的资源。
一般来说,最基本的是基于IP的压力控制。这是因为,如果基于域名,一个域名可以对应多个IP(许多大型站点)或多个域名的同一个IP(小型站点共享IP)。实际上,根据IP和域名的不同条件,通常会进行压力放置控制。另一方面,站长平台也推出了压力反馈工具,站长可以手动放置对自己网站的捕捉压力,百度spider将根据站长的要求优先控制压力。
对同一站点的捕获速度控制通常分为两类。一个是一段时间内的捕获频率。第二,在一段时间内抓住流量。根据同一站点的不同,捕获速度也会随着时间的不同而不同。例如,在夜深、月亮暗的时候捕捉可能会更快,根据网站类型,错开普通用户访问的最高点是主要的想法。不断调整(大卫亚设,Northern Exposure(美国电视剧),不同的网站的捕捉速度不同。
三,新链接重要程度判断
Baiduspider在构建数据库之前对页面进行了初步内容分析和
链接分析,通过内容分析决定该网页是否需要建索引库,通过链接分析发现更多网页,再对更多网页进行抓取——分析——是否建库 & 发现新链接的流程。理论上,Baiduspider 会将新页面上所有能 “看到” 的链接都抓取回来,那么面对众多新链接,Baiduspider 根据什么判断哪个更重要呢?两方面:第一,对用户的价值
- 内容独特,百度搜索引擎喜欢 unique 的内容
- 主体突出,切不要出现网页主体内容不突出而被搜索引擎误判为空短页面不抓取
- 内容丰富
- 广告适当
第二,链接重要程度
- 目录层级——浅层优先
- 链接在站内的受欢迎程度
四,百度优先建重要库的原则
Baiduspider 抓了多少页面并不是最重要的,重要的是有多少页面被建索引库,即我们常说的 “建库”。众所周知,搜索引擎的索引库是分层级的,优质的网页会被分配到重要索引库,普通网页会待在普通库,再差一些的网页会被分配到低级库去当补充材料。目前 60% 的检索需求只调用重要索引库即可满足,这也就解释了为什么有些网站的收录量超高流量却一直不理想。
那么,哪些网页可以进入优质索引库呢。其实总的原则就是一个:对用户的价值。包括却不仅于:
- 有时效性且有价值的页面:在这里,时效性和价值是并列关系,缺一不可。有些站点为了产生时效性内容页面做了大量采集工作,产生了一堆无价值面页,也是百度不愿看到的 .
- 内容优质的专题页面:专题页面的内容不一定完全是原创的,即可以很好地把各方内容整合在一起,或者增加一些新鲜的内容,比如观点和评论,给用户更丰富全面的内容。
- 高价值原创内容页面:百度把原创定义为花费一定成本、大量经验积累提取后形成的文章。千万不要再问我们伪原创是不是原创。
- 重要个人页面:这里仅举一个例子,科比在新浪微博开户了,即使他不经常更新,但对于百度来说,它仍然是一个极重要的页面。
五,哪些网页无法建入索引库
上述优质网页进了索引库,那其实互联网上大部分网站根本没有被百度收录。并非是百度没有发现他们,而是在建库前的筛选环节被过滤掉了。那怎样的网页在最初环节就被过滤掉了呢:
- 重复内容的网页:互联网上已有的内容,百度必然没有必要再收录。
- 主体内容空短的网页
- 有些内容使用了百度 spider 无法解析的技术,如 JS、AJAX 等,虽然用户访问能看到丰富的内容,依然会被搜索引擎抛弃
- 加载速度过慢的网页,也有可能被当作空短页面处理,注意广告加载时间算在网页整体加载时间内。
- 很多主体不突出的网页即使被抓取回来也会在这个环节被抛弃。
- 部分作弊网页
更多关于aiduspider抓取系统原理与索引建库,请前往百度站长论坛查看文档。












